LQO Evaluation
An evaluation suite for Learned Query Optimizers.
Paper
Motivation
Traditional query optimizers face limitations in today’s data-intensive landscape due to rigid assumptions like attribute independence and uniform distributions. Learned Query Optimizers (LQOs) aim to overcome these challenges by using machine learning to infer execution plans from data and past executions.
As research accelerates, a rigorous analytical framework is essential to understand the design choices driving performance. This work introduces a structured evaluation across five core dimensions—performance, robustness, learning, decision-making, and generalization—to unlock the full potential of LQO systems.
The Anatomy and Diversity of LQOs
Learned Query Optimizers (LQOs) represent a highly diverse landscape of architectures, ranging from End-to-End neural planners to Learned Assistants that steer traditional engines via hints. However, existing evaluations struggle to cope with this diversity due to limited benchmark pools, incosistent train-test split philosophies, varying hardware, and a narrow focus solely on performance metrics.
To enable a structured comparison, we deconstruct these systems into five core axes:
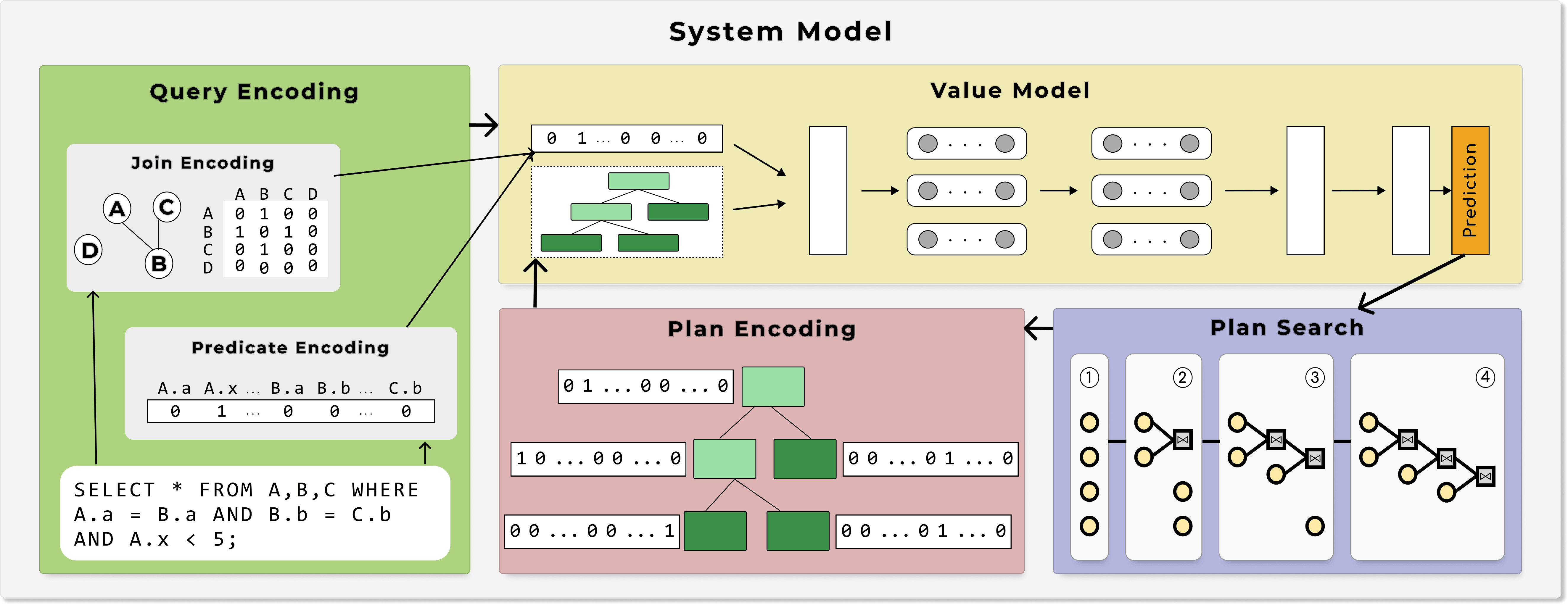
- System Model: Embodies the optimization process; Query as input, finds i. join order, ii. access paths, and iii. physical operators.
- Value Model: The predictive engine; Evaluates the performance of candidate optimization strategies.
- Query Encoding: Transforms raw SQL queires into structured representations
- Plan Encoding: Translates the evolving query execution plans into the representation required by the Value Model.
- Plan Search: Defines how a system traverses the query plan space.
Experimental Setup
Our evaluation framework addresses previous inconsistencies in benchmarks and hardware controls by implementing objective, cross-system comparisons. We evaluate 7 state-of-the-art LQOs against a unified PostgreSQL v12.5 baseline in a single, standardized environment.
The suite utilizes eight diverse benchmarks, including JOB for real-world correlations , TPC-H/DS for decision support , and SQLStorm for complex LLM-generated queries. To measure model stability, we introduce strict experimental controls for Query Order (e.g., Ascending Complexity) and Training Policies (Epoch-based vs. Loss-based).
Beyond basic performance, the setup investigates internal decision-making by evaluating access-path selection across varying selectivities and testing join operator choices as query complexity grows. Furthermore, we assess generalization by subjecting models to unseen queries , schema modifications , and temporal covariate shifts in data distributions.
Our Research Showed
Our systematic evaluation highlights several critical insights into the behavior and performance of Learned Query Optimizers (LQOs).
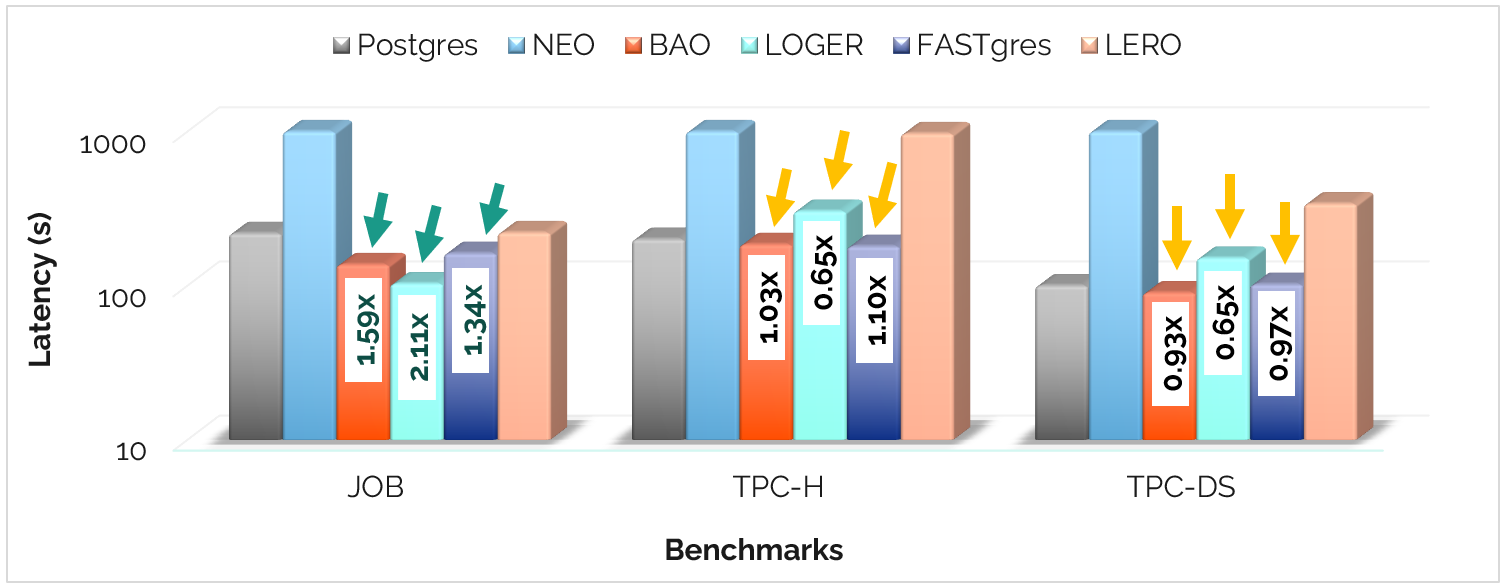
Performance - Can LQOs surpass Postgres?
While LQOs demonstrate significant potential, their impact varies by benchmark. We observe that LQOs can outperform Postgres, especially on datasets characterized by high skewness and complex correlations.
- High Gain: In JOB, systems like LOGER achieve up to 2.11x speedup over Postgres.
- Narrow Margin: On TPC-H and TPC-DS, the gap narrows significantly, with some LQOs struggling to match or only marginally surpassing the base optimizer.
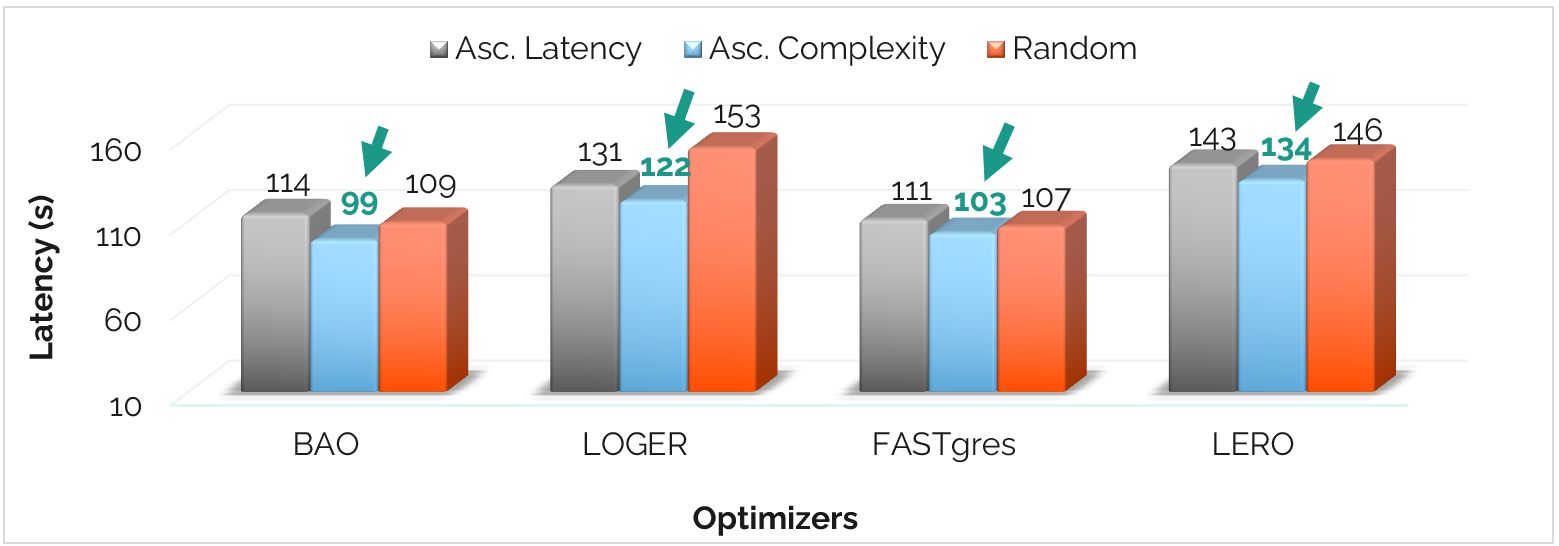
Learning - Does query ordering matter?
The sequence in which an LQO "sees" queries during training significantly affects its stability and ultimate latency.
- Ascending Complexity: Training on simple queries first leads to the most effective learning, improving latency by 6.6% over random ordering.
- Curriculum Effect: Strategic ordering saves up to 39 seconds in total execution time on the Join Order Benchmark.
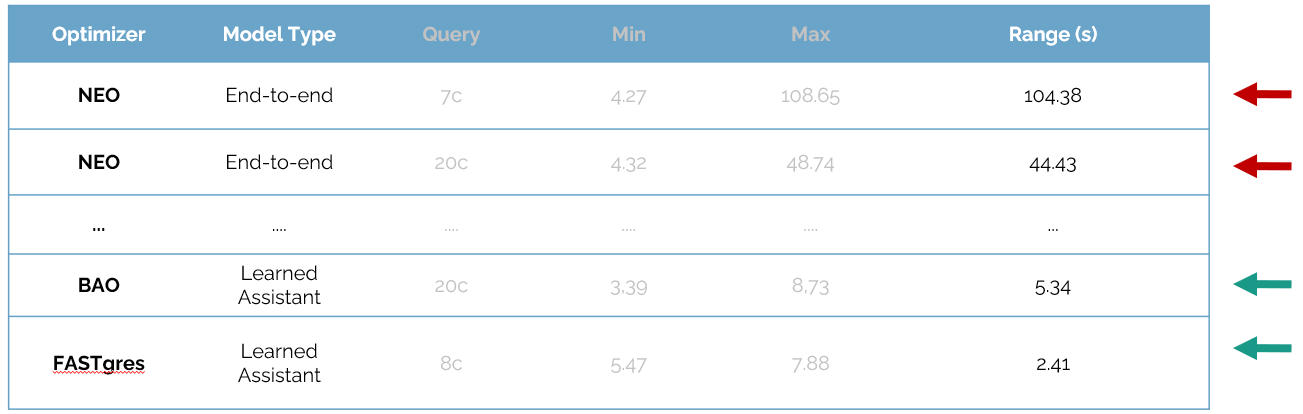
Consistency - Same query, same execution time... right?
Predictability is key for production databases. Our tests reveal a stark contrast between architectural approaches:
- Reliability Gap: End-to-end models like NEO can show high variance (up to 104s range) if their Value Models are unreliable.
- Assistant Stability: Learned Assistants (BAO, FASTgres) provide far more consistent results by reproducing identical hints across runs.
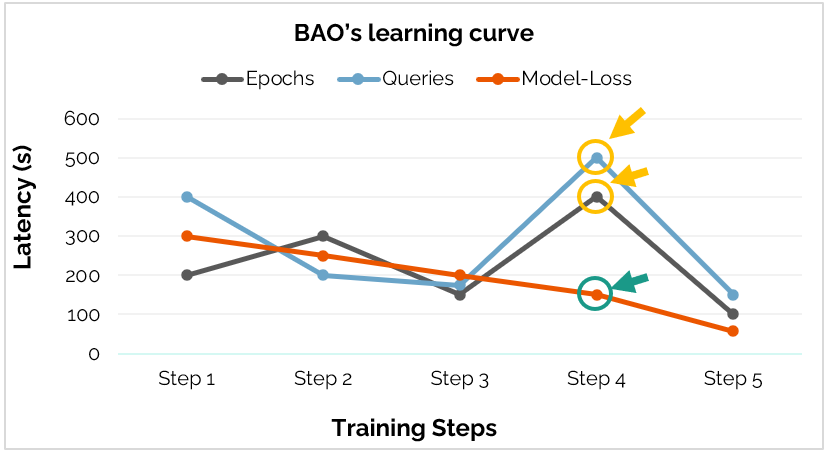
Learning Trajectories - How to measure progress? How far is far enough?
We evaluated three training policies: Epoch-based, Queries-seen, and Model-loss. Our results show they are not equivalent.
Training should be dynamic and based off of model convergence.
- Regression Risk: Fixed stopping points (Epochs or Queries) often hit performance minima and significant regressions mid-training.
- Convergence: Loss-based training proved most consistent for capturing meaningful progress.
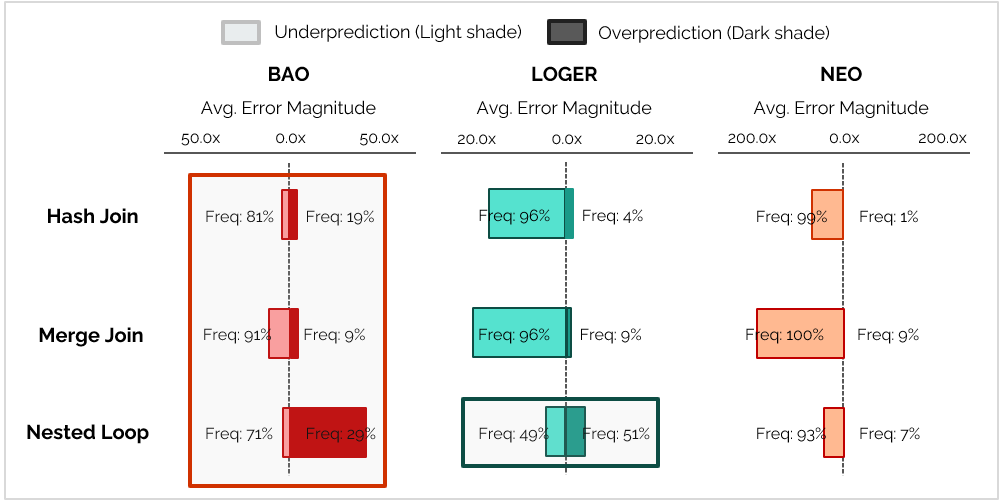
Join Operator Predictions - How accurate can they be?
The accuracy of an LQO is heavily tied to its underlying cardinality estimation strategy:
- Inherited Tendencies: Systems relying on classic optimizer cardinality estimates (like BAO) inherit the classic estimation tendencies, like robustness in Hash Join cost estimations and increased cost estimation errors for Nested Loops.
- Learned Potential: LOGER-like systems that model their own estimates show immense potential, significantly reducing error magnitudes across the Nested Loop join - the workload's most prominent operator and the operator most sensitive to cardinality estimation errors.
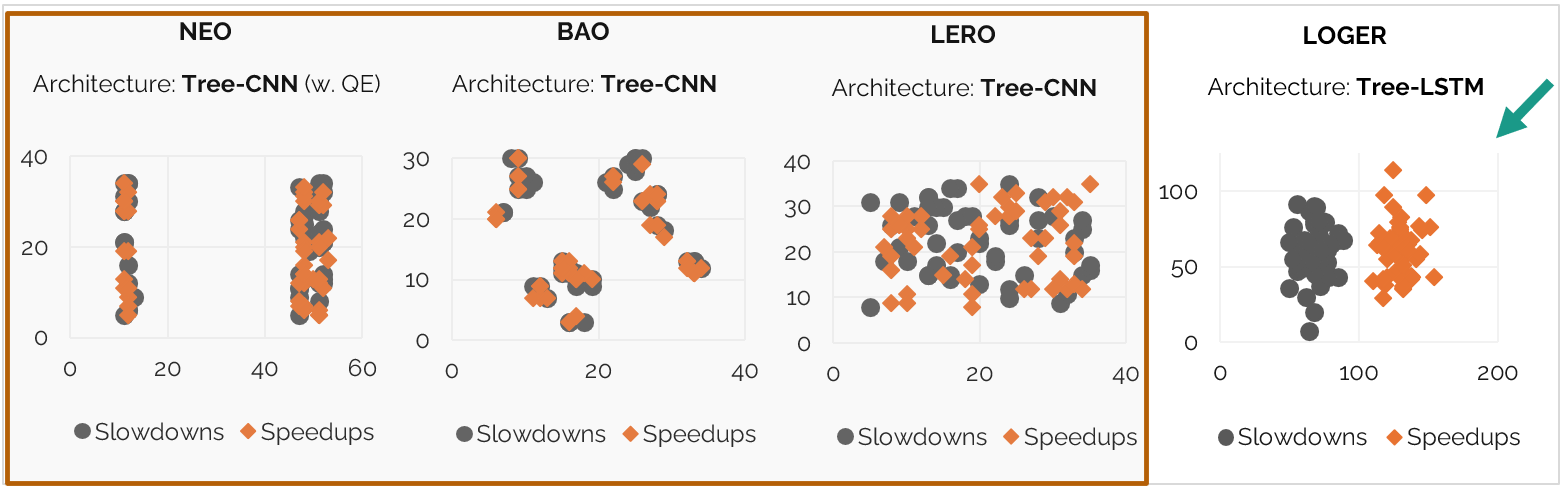
Embedding Analysis - Do LQOs know their plans?
The internal representation of query plans—how the model "sees" the search space—is the primary driver of optimization quality.
- Unstructured Space: Architectures utilizing Tree-CNN (NEO, BAO, LERO) often fail to produce a structured latent space, mixing speedups and slowdowns indiscriminately.
- The Power of Representation: LOGER's Tree-LSTM architecture creates a well-structured embedding space, clearly separating high-performance plans from regressions.
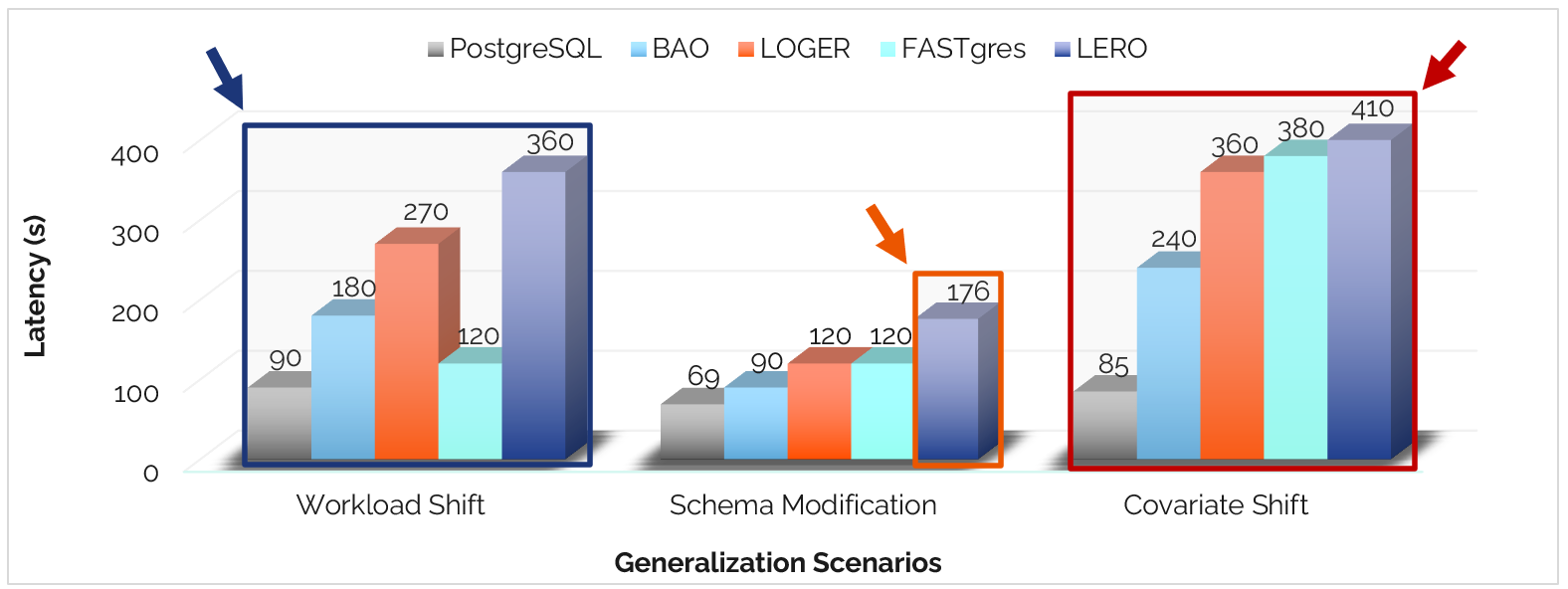
Generalization - New conditions, what happens now?
Generalization remains an unsolved problem for LQOs. When faced with environments that differ from their training data, performance often degrades sharply:
- The Novelty Barrier: Most systems struggle significantly with novel joins and shifting dataset distributions (Covariate Shift).
- Encoding Pitfalls: One-hot schema encodings are fragile.